The bottom line
Machines already generate the data needed to predict their own failures. AI predictive maintenance connects that data to trained models that detect failure signatures days before breakdown - cutting unplanned downtime by up to 45% and repair costs by up to 40%. The technology is not the constraint. Most factories just are not listening yet.
In This Article
Introduction
The average large manufacturing plant loses approximately USD 253 million per year to unplanned downtime (Siemens, True Cost of Downtime 2024). Between 2019 and 2024, the hourly cost of these outages rose by roughly two-thirds — the Siemens report puts the increase at around 65%. These are not just numbers on a balance sheet. They represent missed deadlines, idle crews, and production schedules that take days to recover from.
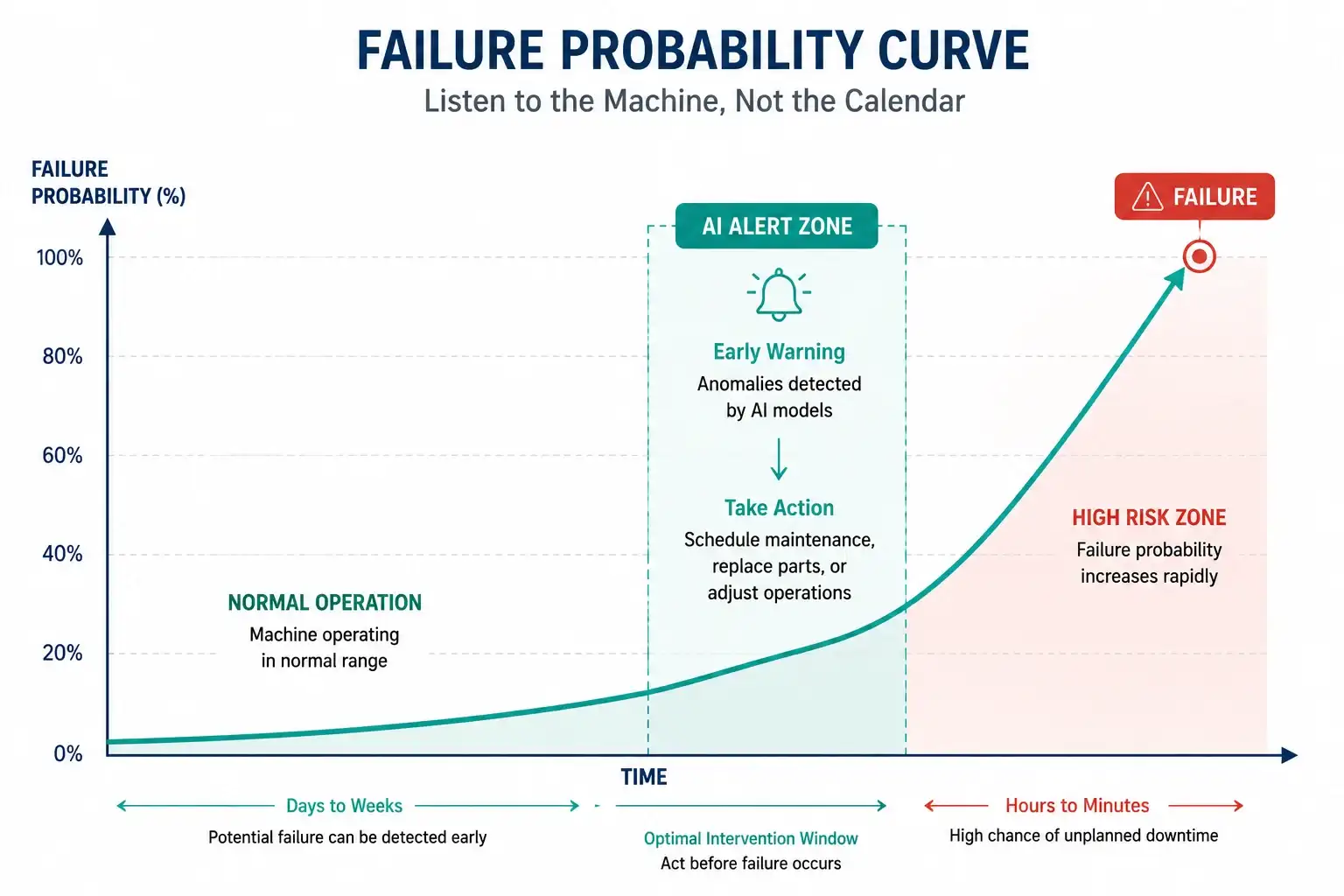
Most of these failures are not random. Machines broadcast their impending failure through data signals days - sometimes weeks - before they actually stop. The problem is not a lack of data. It is that most industrial maintenance programmes are not designed to listen to it.
Why Traditional Maintenance Plans Keep Costing Manufacturers a Fortune
Most facilities are stuck in a cycle of reactive or preventive maintenance, and both approaches have fundamental limitations that data intelligence has now made avoidable.
Reactive maintenance waits for equipment to fail before acting. Repair costs are significantly higher under emergency conditions. The resulting unplanned downtime ripples across the entire production schedule, compounding the financial impact far beyond the cost of the repair itself.
Preventive maintenance follows a fixed calendar regardless of the actual health of the machine. It is essentially a structured guess. A $1,000 bearing gets replaced every six months because a manual specifies it. If that bearing still had 40% of its useful life remaining, money has been wasted. If it fails at month five, the calendar provided no protection.
Condition-based maintenance moves organisations away from wasteful scheduled replacements and toward a model where intervention happens based on actual wear - at exactly the right moment.
What AI Predictive Maintenance Actually Is
AI predictive maintenance in manufacturing is the use of machine learning models and IoT sensors to continuously monitor equipment health and detect early warning signs of failure before they result in a production stoppage.
It is not a simple high-or-low alarm on a single sensor. It is a system that analyses vibration, temperature, acoustics, power consumption, and pressure simultaneously. These data streams feed into a predictive maintenance platform trained on historical failure data for each specific asset type.
The AI learns to recognise the specific failure signature that precedes a breakdown - often days before a human technician would notice a physical symptom or hear an unusual noise. This is the foundation of modern equipment failure prediction.
How AI Predicts Equipment Failure in Manufacturing
The process follows a clear four-stage data pipeline that removes guesswork from maintenance decision-making entirely.
Stage 1 - Continuous Data Collection: Everything begins with the sensors. Predictive maintenance IoT devices capture vibration frequencies, temperature gradients, acoustic signatures, and electrical consumption patterns continuously and automatically. Every operational pulse of every monitored asset is recorded without manual intervention.
Stage 2 - Baseline Establishment: The AI establishes what normal looks like for each specific asset under each specific operating condition. Normal for a press running heavy-gauge steel is different from normal for the same press running light-gauge aluminium. This asset health monitoring accounts for operational variables that standard threshold alarms consistently miss.
Stage 3 - Anomaly Detection and Failure Signature Recognition: When sensor readings begin to deviate from the established baseline in a pattern the model associates with an impending failure, the platform generates a targeted alert. The system identifies the specific failure mode and estimates how much production time remains before a total stoppage occurs.
Stage 4 - Recommended Action Delivery: The system delivers a specific, actionable task to the maintenance team. It does not simply indicate that Machine 3 is running hot. It states that Machine 3, Motor B cooling fan is failing, estimated failure in 48 hours, Part 12345 required. That level of specificity is what turns a data signal into a maintenance decision.
The Numbers: Predictive vs Preventive Maintenance
The business case for an AI-based predictive maintenance platform is well documented and consistent across independent sources.
AI maintenance in manufacturing can reduce repair costs by up to 40% and decrease unexpected downtime by as much as 45%. According to McKinsey, predictive maintenance can lower total maintenance costs by 10% to 40% while significantly extending equipment lifespan.
Emergency repairs typically require 3 to 5 times more labour hours than planned maintenance interventions (industry studies converge on this range, with some sources citing higher multipliers for catastrophic failures). When AI predictive maintenance is in place, savings accumulate not just on parts but on the high-cost labour associated with emergency repair shifts that disrupt the entire team's planned workload.
The $253M annual downtime figure is not an outlier - it is the average for a large plant. The gap between that number and what best-in-class predictive operations spend on maintenance is where the ROI conversation starts.
How to Implement Predictive Maintenance in a Factory
Implementation does not require replacing existing infrastructure or transforming every asset simultaneously. A phased, targeted approach delivers faster results and clearer ROI at each stage.
Start with the highest-risk assets. Identify the machines whose failure would cause the greatest disruption to overall throughput. This is where predictive maintenance delivers the most immediate return and where the business case for broader rollout is most quickly proven.
Connect the data sources. Retrofit IoT sensors on legacy machines that lack built-in digital connectivity. Bridge existing SCADA and PLC data into a single analytics layer where the AI platform can access it continuously.
Train the model. AI requires historical context to learn from. Historical maintenance logs, past failure records, and operational data help the machine learning model recognise the specific failure patterns relevant to each asset in the operation.
Scale progressively. Once results are proven on a single critical line, extend coverage systematically across the rest of the facility. Each additional asset adds more data, improves model accuracy, and increases the overall return on the platform investment.
What "Listening to the Machine" Runs On
Listening is, in architecture terms, a connectivity-then-modelling pipeline. Sensor data — vibration, temperature, acoustic, power draw — streams off the PLCs over OPC-UA or MQTT, with retrofit IoT sensors filling in on assets that have no digital output, through Azure IoT Hub into Microsoft Fabric Real-Time Intelligence. The raw signal lands in OneLake, so years of high-frequency history sit in one governed Delta Lake table rather than a separate vendor appliance per asset class. That single historian is the thing most plants have never actually had, and it is what makes the model trainable.
On top sits the modelling and the response. Anomaly detection runs against the live stream in Fabric, and once an asset has enough labelled failure history a trained model recognises its specific failure signature. The alert does not stop at a dashboard — it writes back through Azure Data Factory into the CMMS as a work order with the failure mode, the estimated time to failure, and the part required, while a Power BI semantic model gives the reliability engineer one view of alert accuracy and downtime prevented. The four-stage pipeline — collect, baseline, detect, act — maps directly onto this stack.
Building it on one OneLake foundation is what makes it scale economically. The same data that powers predictive maintenance also feeds OEE and the wider manufacturing analytics estate without a second integration — you instrument once and reuse, rather than running a separate project for every metric. That reuse is the difference between a single-asset pilot and a plant-wide capability.
Where This Still Breaks
The honest constraint is sparse failure data. The critical assets you most want to protect fail rarely by design, so they offer the fewest labelled examples to train on — and on an asset that has failed twice in three years, no model has enough signal. Condition-based thresholds and physics-based rules are the right answer there, not machine learning, and the "initial visibility in weeks, reliable prediction in months" timeline is honest precisely because the model needs to observe real operating conditions before it earns trust.
False alarms are the second failure mode, and they are a trust problem more than a technical one. A model that flags 30 phantom failures a week gets switched off by the maintenance team regardless of its accuracy on the real ones — so the baseline has to account for operating context (heavy-gauge versus light-gauge runs are different normals), and the false-positive rate has to be monitored and the model retrained as conditions drift. An ignored alert is worse than no alert.
And the limit everyone underestimates: a prediction nobody acts on is wasted. If the alert-to-action cycle is longer than the time-to-failure window, or the work order never reaches the technician with the right part, the signal is just noise with a timestamp. Predictive maintenance is a workflow and a CMMS-integration problem as much as a modelling one — which is why connecting the data that already exists, not buying a cleverer model, is where the return actually comes from.
On a rarely-failing critical asset there is not enough labelled history to train a model — condition-based thresholds are the honest answer. And a prediction the maintenance team does not trust gets ignored, however accurate it is.
Stop Firefighting
Every machine on the production floor is already generating the data needed to predict its own failures. Most plants are simply not listening to it.
Predictive maintenance in manufacturing turns those machine signals into a continuous early warning system that protects production schedules, reduces costs, and gives maintenance teams the confidence to act before the breakdown rather than scrambling to recover after it.
An AI predictive maintenance strategy does not require replacing existing infrastructure. It requires connecting the data that already exists and letting a trained platform do what no human team can do at scale: listen to every machine, simultaneously, all the time.
Ready to stop the fix-it-after-it-breaks cycle? Schedule a discovery call to see how MyData Insights helps manufacturers build a predictive maintenance platform on their existing infrastructure.
Every machine on the production floor is already generating the data needed to predict its own failures. Most plants are simply not listening to it. An AI predictive maintenance strategy does not require replacing existing infrastructure - it requires connecting the data that already exists and letting a trained platform do what no human team can do at scale: monitor every asset, simultaneously, all the time.
Free Assessment
Where does your operation sit on the data maturity curve?
8 questions. 3 minutes. You get a scored breakdown across data infrastructure, analytics readiness, and automation potential — with a specific next step for your industry.